Durante la última semana fuimos testigos de un nuevo enfrentamiento humano-computador: AlphaGo, una Inteligencia Artificial desarrollada por Google, jugó cinco partidas del juego de estrategia Go contra Lee Sedol, el mejor jugador de la última década.

Después de 3 juegos donde Sedol fue derrotado por AlphaGo, una victoria en la cuarta partida subió los ánimos del campeón. Sin embargo, su alegría duró poco: durante la madrugada del 15 de marzo (hora chilena), la Inteligencia Artificial lo superó en la quinta y última partida, sobreponiéndose al jugador profesional con un marcador 4-1.
Go vs. Ajedrez
La primera vez que un computador derrotó a un humano en un juego de estrategia fue en 1997, cuando Deep Blue venció al entonces campeón mundial de ajedrez Garry Kasparov. Sin embargo, la victoria de AlphaGo es mucho más significativa, ya que el Go es un juego mucho más complejo.

El Go es un juego de estrategia tradicional chino, cuyos orígenes se remontan hasta unos 2.500 años atrás. A pesar de sus reglas extremadamente sencillas (solo hay 2 reglas para cada movimiento), resulta muy difícil de dominar. Como ejemplo: un juego de ajedrez tiene 20 jugadas de apertura posibles, mientras que el Go tiene 361. El número de juegos posibles en un tablero de ajedrez es de 10¹²⁰; para el Go, son 10⁷⁶¹: un juego de Go tiene más posibles combinaciones que el número de átomos que existen el Universo.

¿Qué es AlphaGo?
AlphaGo es un programa computacional desarrollado por Google DeepMind. Esta no es la primera incursión de Google en Inteligencia Artificial: el año pasado un equipo de investigación desarrolló DeepDream, la red neuronal que genera extrañas imágenes.

Los métodos usuales de Inteligencia Artificial para juegos de estrategia se basaban en la fuerza bruta: buscar todas las jugadas posibles y sus consecuencias. Esto es lo que hacía Deep Blue durante las partidas de ajedrez. Sin embargo, dada la complejidad del juego de Go, abordar una partida de esa forma no tiene sentido. Es por eso que todos los intentos previos de computadoras que jugaban Go tenían un desempeño digno de amateurs, con bajísimas probabilidades de ganarle a los mejores jugadores del mundo.
El equipo de DeepMind se decidió a crear una Inteligencia Artificial que tuviese un funcionamiento algorítmico más cercano al pensamiento humano. Después de cada jugada de su oponente, AlphaGo analiza todos los distintos resultados posibles de la partida. Este método se conoce como Árbol de Búsqueda Monte Carlo (ABMC), y es ampliamente usado en software que modela procesos de decisión. Pero, a diferencia de los casos anteriores, AlphaGo usa ABMC en conjunto con Redes Neuronales Artificiales que le ayudan a guiar su búsqueda: de este modo, su camino se inclina hacia los escenarios que le son favorables, haciendo más rápida la búsqueda de la jugada adecuada. Esta combinación de mecanismos hace que AlphaGo haga miles de búsquedas menos por jugada que Deep Blue.
El problema de analizar cada posición del juego para estimar quién será el ganador es tan complejo que los expertos creían que aún faltaban décadas para que llegara a existir una Inteligencia Artificial que pudiera resolverlo. AlphaGo les demostró que estaban equivocados.
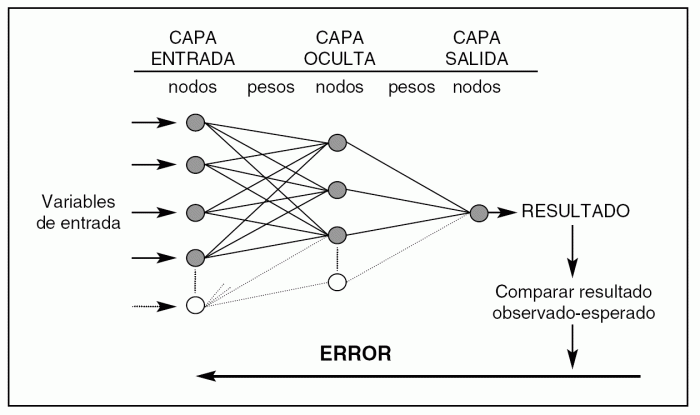
Como hemos comentado antes, una Inteligencia Artificial no aprende por sí sola: debe ser entrenada. AlphaGo fue entrenada «viendo» más de 30 millones de jugadas de Go, obtenidas de videos de partidas entre humanos expertos. Además, la máquina es capaz de competir contra ella misma: sus procesadores pueden dividirse a la mitad, equivalente a dos jugadores distintos. AlphaGo es capaz de jugar contra ella misma más de un millón de veces al día. Luego de todo este entrenamiento, sus creadores estimaron que AlphaGo podía predecir la próxima jugada de su oponente un 57% de las veces.
El primer desafío de AlphaGo se realizó en privado. El 28 de enero de 2016, con la publicación del paper en Nature, el equipo de DeepMind anunció que AlphaGo había derrotado, en octubre de 2015, al campeón europeo de Go Fan Hui con un indiscutible 5-0. Y no fue el único anuncio: ahora pondrían a AlphaGo a prueba de manera pública, al enfrentarse en cinco partidas al mejor jugador de Go de la última década, el surcoreano Lee Sedol.
Las tres primeras partidas: superioridad artificial
En las tres primeras partidas, Sedol fue derrotado sin clemencia por AlphaGo. Durante el primer juego, las jugadas de AlphaGo desconcertaron a los comentaristas, que tardaron varias jugadas más en darse cuenta que la Inteligencia Artificial tenía la partida totalmente dominada. Jugando de una manera que sería poco convencional para un ser humano, AlphaGo conseguía que Sedol se pusiera más nervioso con cada minuto que pasaba. Luego de casi 4 horas de juego y 186 movimientos, el humano tuvo que rendirse ante la superioridad de la máquina.
El segundo juego duró casi 6 horas y tuvo 211 movimientos. La tercera partida, 6 horas de juego y 176 movimientos. Las tres primeras partidas del desafío terminaron con la renuncia de Sedol.

La cuarta partida: revancha humana
Después de perder el tercer juego, Lee Sedol se reunió con otros jugadores y pasaron varias horas analizando los videos de las partidas. Su plan era lograr detectar alguna debilidad en el juego de AlphaGo, y lo lograron: la Inteligencia Artificial parecía seguir un esquema de juego llamado «souba«, en el cual el jugador estima los riesgos de cada jugada y elige la menos peligrosa.
Sedol comenzó la cuarta partida con un juego más agresivo que en las tres anteriores. Su estrategia fue rodear completamente a AlphaGo, quitándole territorio en el tablero, y haciendo así que su estrategia fuera menos relevante en cada jugada.
Y dio resultados: AlphaGo cometió un error en el movimiento 79; hasta entonces tenía un 70% de probabilidad de estimar la siguiente jugada de su oponente. Debido a su error, para el movimiento 87 su capacidad de adivinar la próxima jugada ya se había desplomado. Desde el movimiento 87 en adelante su desempeño fue en picada, hasta que en el movimiento 141 la probabilidad de estimar correctamente el próximo paso del oponente era tan solo de un 20%. Debido a un nivel de certeza tan bajo, AlphaGo se rindió ante Sedol.

La quinta partida: AlphaGo contraataca
Todos esperaban con ansias la quinta partida y final, que se jugó el 15 de marzo en Seúl. Sedol, más motivado con su victoria previa, llegó preparado con la misma estrategia que en el juego anterior. Sin embargo, esta vez no obtuvo los resultados esperados. Un lloroso Lee Sedol tuvo que rendirse frente a la superioridad de la Inteligencia Artificial en el juego.

Si bien todavía no hay análisis cuidadosos de la partida, que duró alrededor de cinco horas, los desarrolladores de AlphaGo han señalado que se encuentran felices, ya que la máquina logró sobreponerse a una mala jugada que realizó en los primeros movimientos.
El futuro de la Inteligencia Artificial
Para muchos expertos, aún faltaban décadas para llegar a una Inteligencia Artificial tan avanzada con AlphaGo. Claramente la investigación en el área está avanzando mucho más rápido de lo esperado: cada vez son más las máquinas que parecen presentar un nivel de razonamiento similar al pensamiento humano. Recordermos que, como decía el padre de la computación Alan Turing, lo importante no es que una máquina piense exactamente como lo hace una mente humana, sino que pueda imitar sus resultados.
AlphaGo aún tiene muchos detalles que mejorar, y seguirá aprendiendo. Por ahora, el equipo de DeepDream ha señalado que comenzará a aplicar sus algoritmos de aprendizaje en materias como salud pública y robótica. Si bien una máquina que aprenda a jugar Go puede no parecer un gran aporte a la humanidad, los principios matemáticos y los algoritmos que van detrás pueden ser aplicados en muchas áreas distintas, desde mejorar los resultados de las búsquedas de Google hasta desarrollar autos que se manejen solos.
La Inteligencia Artificial es el paradigma de la computación del futuro. Cada vez son más y más las aplicaciones que la utilizan y donde la usamos día a día, sin siquiera darnos cuenta. No cabe duda que los próximos años traerán grandes desarrollos al respecto.
Hay que revisar el concepto de inteligencia. cuando se prepara a una maquina para realizar un trabajo y el trabajo se hace de la manera esperada entonces no hay inteligencia (por muy complicado que sea este trabajo), cuando la maquina hace cosas inesperada de manera autónoma entonces podemos hablar de inteligencia. Con la PSU y el Simce estamos preparando una sociedad de maquinas tontas que no tienen una autodeterminación en su manera de pensar y actuar. Sospecho que a Albert Einstein no le hubiese ido bien en el sistema educativo chileno.
En términos humanos, la definición de inteligencia es compleja. Sin embargo, en el contexto de máquinas e inteligencia artificial, «inteligencia» se define como la capacidad de la máquina para obtener un resultado similar al que se obtendría con el razonamiento humano.
La definición de inteligencia es distinta en el caso de humanos que en el caso de computadores. Por supuesto que hay mucha inteligencia detrás de una máquina que logra realizar hazañas como estas.
Igual es raro que digas que hay dos tipos de inteligencias, uno podría pensar en una definición de inteligencia para hombres y otra para mujeres o también para otros animales. La inteligencia al igual que el concepto de vida no tienen una definición formal pero si podemos hacer una abstracción sobre ellas, y en eso lo que hacen las maquinas en la actualidad esta muy lejos del concepto de inteligencia que opera sobre los sistemas biológicos.
Te invito a leer este artículo donde profundizo más en la definición de inteligencia en el sentido de inteligencia artificial: https://primerfoton.cl/2015/08/20/que-es-y-que-no-es-una-inteligencia-artificial-parte-1/
Saludos